
Until recently, I usually ignored floating point arithmetic errors in my applications. In graphics you are naturally interested in speed and what does it matter if an object is translated wrongly a thousands part of a pixel? On the other hand: how hard can it be to test if a point lies within a sphere? As formula this is very straight forward: len(center-point) <= radius. Unfortunately this operation involves a sum of squares and the rounding errors indeed lead to wrong classifications. I don't even know how to test if a point is inside a sphere correct without unlimited precision math.
This is a post about different tricks and algorithms to avoid numerical issues. Especially in ray casting and intersection methods I got some artifacts in the past. Many of them occurred to me while writing my math and intersection library Epsilon.
Most of the knowledge here is drawn from the article "What Every Computer Scientist Should Know About Floating-Point Arithmetic" [Go91] and some other articles. I will not go as deep as the linked articles. Instead I will collect what are the most useful algorithms and show some examples when it makes sense to use them. Also, I won't go into details of why there is a numerical issue - for that I recommend to read [Go91].
In the graphs below I computed the relative error of the respective expressions. This is calculated as the result minus the true result divided by the true result, i.e.
abs((x-ref)/ref). Thereby, the true result is computed using the most correct expression in double precision.
Rounding
Rounding is the root of all evil. Floats have the nice property that they always have (more or less) the same relative precision. That means, it doesn't matter if a number is small or huge, as long as it is not too small (underflow) or too large (overflow). Still, the number of digits is limited. Lets assume we have 3 digits precision in decimal system, than adding 100e1 and 1 gives 100e1. So the 1 had no effect at all, since the true result 1001 was rounded to three digits. In most cases the rounding during addition is not fatal, because the error is relatively small (all 3 stored digits are correct). Addition and subtraction may only have an error in the last digit, i.e. they will not be far away from the true result. If rounding to the closer number the error is at most 0.5 ulp (units is the last place).
The point where rounding makes things bad is if errors accumulate. In the worst case catastrophic cancellation can happen, where a subtraction of similar numbers reveals a previous error. An example from [Go91]: Again we have decimal numbers with 3 digits: a=1.22, c=2.28, b=3.34 and want to compute b*b-4*a*c. The exact result is 0.0292. In limited precision it is b*b=11.2 (0.5 ulp), 4*a*c=11.1 (0.5 ulp) and finally 0.1 (70 ulp !).
1-x² and x²-y²
Lets start with the  smallest term.
1-x*x is very useful in trigonometric expressions, since
sin^2 + cos^2 = 1. For example: this can be used for the compression of normal vectors in polar coordinates. So, what is the problem of this expression?
smallest term.
1-x*x is very useful in trigonometric expressions, since
sin^2 + cos^2 = 1. For example: this can be used for the compression of normal vectors in polar coordinates. So, what is the problem of this expression?
It is catastrophic cancellation, because x is squared and then subtracted, which is the most basic example where this kind of error occurs.
It is possible to write the expression using the third binomial formula
(1-x)*(1+x), which is more robust. This form has a bigger error in general, but as the graph shows, its error does not increase if both numbers are very similar and is very small otherwise. However, a maximal error of 0.012% in the first form is not that dramatic for most applications.
Note, that the same trick applies to
x*x-y*y which can be reformulated to
(x-y)*(x+y)
Quadratic Equation
 There are many algorithms which require the roots of a quadratic polynomial, e.g. a ray-sphere intersection. The basic expression we want to solve is ax² + bx + c = 0 for which the known solution is
There are many algorithms which require the roots of a quadratic polynomial, e.g. a ray-sphere intersection. The basic expression we want to solve is ax² + bx + c = 0 for which the known solution is

Again, it is possible to use the third binomial formula and multiply the term with the denominator using the inverted sign [X05]:

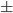 changed and we get the subtraction for the two results reversed. A stable implementation needs to check which of the two formulas is better for which x and than use one of the two different terms.
changed and we get the subtraction for the two results reversed. A stable implementation needs to check which of the two formulas is better for which x and than use one of the two different terms.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// Returns two solutions with x1 >= x2 if there are solutions void solveSquarePoly(float a, float b, float c, float& x1, float& x2) { float discriminant = b*b - 4.0f*a*c; // ... handle discriminant < 0 ... float dsqrt = sqrt(discriminant); if(b > 0) { x1 = (-b - dsqrt)/(2.0f*a); x2 = -2.0f*c/(b + dsqrt); } else { x1 = -2.0f*c/(b - dsqrt); x2 = (-b + dsqrt)/(2.0f*a); } } |
ln(1+x) and exp(1+x,n)
 For small |x|, 1+x discards many digits, so both expressions will be inaccurate. The later can be useful in numerical integrations (e.g. simulation of movement), when there is a grow or decrease over time. It can be expressed using the first one: exp(1+x,n) = exp(n*ln(1+x)) which leaves us with the problem of ln(1+x) to be inaccurate. Well, if you look at the graph it is not thaaat important. x must be really close to zero, before something bad happens.
For small |x|, 1+x discards many digits, so both expressions will be inaccurate. The later can be useful in numerical integrations (e.g. simulation of movement), when there is a grow or decrease over time. It can be expressed using the first one: exp(1+x,n) = exp(n*ln(1+x)) which leaves us with the problem of ln(1+x) to be inaccurate. Well, if you look at the graph it is not thaaat important. x must be really close to zero, before something bad happens.
The following code snipped solves this issue. Effectively, the function is multiplied with x/x, where the denominator is replaced by (1+x)-1, which is an estimation of the error made by the summation. [HP82]
|
1 2 3 4 5 6 |
float log1p(float x) { float sum = 1+x; if(sum == 1) return 1; else return x*ln(sum)/(sum-1); } |
You can find a numerical stable log1p method in the math.h (at least in my cpp standard library). Surprisingly, it is slower by a factor of 7 and calls modf, acosf, fdtest and log internally. Seems to be some series expansion inside.
Sum and Variance of Many Numbers
Especially path tracing and other Monte Carlo light transport simulations rely on the law of large numbers. I.e. they converge to the correct result for sufficient many samples. Well, they should, but due to floating point they never will.
First, I experimented with plausible series of 10,000 and 100,000 samples of uniform and exponential distributions. All had shown a systematic underestimation with up to 0.001% error. This is only a problem, if many larger numbers with small variance are added (e.g.  for
for  being a uniform sample) which I did not test, because this is not really likely for rendering applications. Still, I will add a few solutions for completeness. See [Wiki1] and [He05] for more alternatives. The first well known solution is the Kahan summation. It tracks the lost digits in a second register to achieve a constant error bound (trivial summation has an error in the number of samples). However, adding doubles naively is already more precise than Kahan summation with two floats, so it makes only sense if we want to have even more precision than double [Wiki1] or cannot use double (e.g. on GPU).
being a uniform sample) which I did not test, because this is not really likely for rendering applications. Still, I will add a few solutions for completeness. See [Wiki1] and [He05] for more alternatives. The first well known solution is the Kahan summation. It tracks the lost digits in a second register to achieve a constant error bound (trivial summation has an error in the number of samples). However, adding doubles naively is already more precise than Kahan summation with two floats, so it makes only sense if we want to have even more precision than double [Wiki1] or cannot use double (e.g. on GPU).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class PreciseSum { double sum, c; public: PreciseSum() : sum(0), c(0) {} void add(float x) { x -= c; // "Carry" of the lost digits volatile double tsum = sum + x; // volatile to forbid optimization c = (tsum - sum) - x; // 0 if nothing was rounded sum = tsum; } float sum() const { return sum; } }; |
Another option is to recursively compute partial sums. This is quite nice, because computing prefix sums (e.g. for summed area tables) with a parallel algorithm is already more accurate than a linear algorithm.
Beyond the sum of samples we could also be interested in there variance. This time errors can get worse, because if the mean 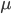 is close to the
is close to the  (with a small variance) we subtract two similar numbers.
(with a small variance) we subtract two similar numbers.

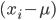 once we know . Both problems are solved by Welford's method explained on [Co08]. I like it, because we don't need to store more than three values which we do anyway (mean, variance and number of samples).
once we know . Both problems are solved by Welford's method explained on [Co08]. I like it, because we don't need to store more than three values which we do anyway (mean, variance and number of samples).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
class PreciseVariance { int m_n; float m_s, m_m; public: PreciseVariance() : m_n(0), m_s(0), m_m(0) {} void addSample(float x) { if(m_n++ == 0) m_m = x; else { float oldM = m_m; m_m = oldM + (x - oldM) / m_n; m_s = m_s + (x - oldM) * (x - m_m); } } int n() const { return m_n; } float mean() const { return m_m; } float variance() const { return m_n>1 ? m_s/(m_n-1) : 0.0; } }; |
 Compared to the often used sum of squares method, which stores x, x*x and n, Welford's algorithm performs much better. In the experiment I used n samples uniformly distributed in [0.5, 1.5] which should be comparable stable (see summation above).
Compared to the often used sum of squares method, which stores x, x*x and n, Welford's algorithm performs much better. In the experiment I used n samples uniformly distributed in [0.5, 1.5] which should be comparable stable (see summation above).
Unfortunately, for more than ~45000 samples the variance in the naive sum of squares method gets negative. Even in the absolute value the error gets larger than 1000% (logarithmic scale!). Besides that catastrophe, all other values have acceptable errors in the 5th to 7th decimal place.
Final Thoughts
I tested a set of recipes for numerical stable computations to see which of them are really necessary in the context of rendering and simulation. Before, I encountered problems in a ray tracing application using ellipsoids leading to geometry misses in my bounding volume hierarchy. So, of course I think using the more stable solution of the quadratic polynomial is a good idea.
Using the third binomial formula is not really necessary, but since it barely changes instruction count/performance it can be used everywhere without thinking.
In the cases of logarithmic functions and summing numbers, errors happen in extremal cases mainly. As long as we do not run into these, which is unlikely in rendering, nothing bad happens with the naive approaches.
However, when using the sums of numbers in some subtraction, as for the computation of variance, I strongly recommend to use a better method. Especially, for unbiased Monte Carlo integration simply adding floats is not enough.
[Co08] Accurately Computing Running Variance, John D. Cook, 2008
http://www.johndcook.com/blog/standard_deviation/
[Co14] Avoiding Overflow, Underflow, and Loss of Precision, John D. Cook, 2014
http://www.codeproject.com/Articles/25294/Avoiding-Overflow-Underflow-and-Loss-of-Precision
[Go91] What Every Computer Scientist Should Know About Floating-Point Arithmetic, David Goldberg, 1991
http://docs.oracle.com/cd/E19957-01/806-3568/ncg_goldberg.html
[HP82] HP-15C Advanced Functions Handbook, Hewlett-Packard Company, 1982
[He05] Binary floating point summation accurate to full precision (Python recipe), Raymond Hettinger, 2005
http://code.activestate.com/recipes/393090/
[Wiki1] https://en.wikipedia.org/wiki/Kahan_summation_algorithm
[X05] 2005, http://people.csail.mit.edu/bkph/articles/Quadratics.pdf